
Algorithmic Squava player Elo ratings

Once upon a time, I wrote four programs that can play a game called squava with lesser or greater amounts of skill.
All four algorithmic players can win against each other, although there are definite differences in apparent skill. I wanted to know what their Elo rating might be.
Two of my algorithmic players use Alpha-beta minimax. The other two algorithmic players use Monte Carlo tree search. Monte Carlo tree search is inherently randomized. I have the Alpha-beta minimax algorithms choose moves randomly that they calculate to have identical “value”. None of the algorithms will necessarily choose the same move twice, in the same situation. This makes them more fun for me, as a human, to play.
Since I haven’t found the best static evaluation function for the Alpha-beta minimaxing players, it’s possible for any of the players to beat any other player periodically. My algorithmic player comparison demonstrates this.
Elo ratings calculation
I read and understood a lot of the document The US Chess Rating System, by Mark E. Glickman and Thomas Doan, March 1, 2024, to do this.
To update an algorithm’s Elo rating after a game of squava, the program calculates:
- K = 800/N, N is the number of games the algorithm has played, including this game.
- E = 1/(1 + 10(R1 - R0)/400) Where R1 is the other algorithm’s rating before the game, and R0 is this algorithm’s rating before the game.
- S = 1, if the algorithm wins, 0.5 if it draws, or 0 if it loses.
- Change in rating of the algorithm is K(S - E)
Because:
- N is possibly different for each algorithm.
- E has different values for each algorithm after a game.
- S is different for the winner and for the loser.
each algorithm potentially gains or loses different amounts of points after a game.
A huge portion of The US Chess Rating system is devoted to calculating an initial rating for a player. I used the “if no other criteria applies” initial rating of 1300, and 14 effective games played for my algorithmic players' initial ratings.
Elo rating evolution
If various algorithms play each for a large number of games, their Elo ratings should evolve to a roughly stable relationship. The K factor gets smaller as the number of games an algorithm has played increases, so the per-game-change in an algorithm’s rating gets smaller.
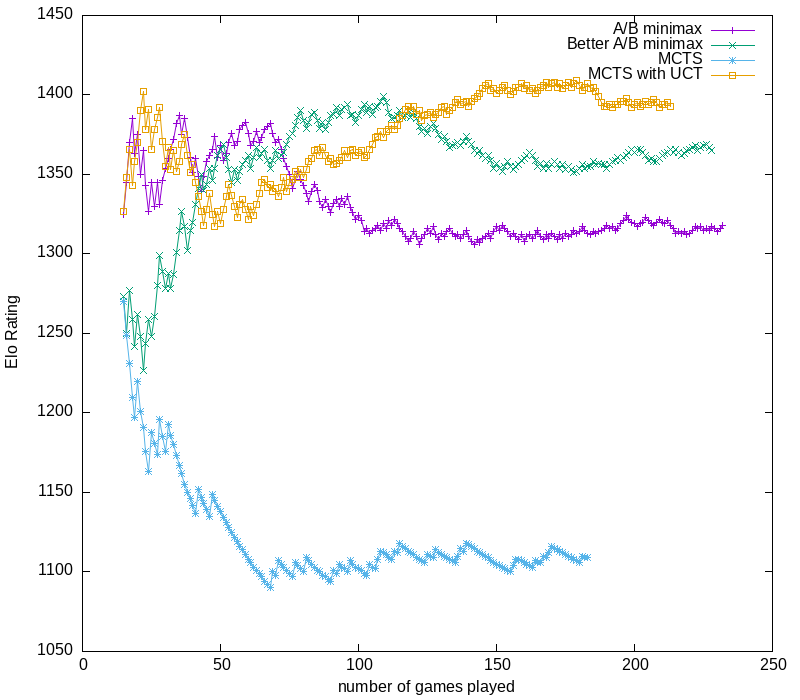
You can see the effect of the K factor in the graph above. Between 0 and 50 games played, ratings jump around drastically, but after about game 100 the jump for a win or loss isn’t as dramatic. By about game 150, the relative positions of the ratings have stabilized.
I ran my find-elo-ratings program 3 times, each for 400 games. Here are the final ratings for the 3 runs:
| Algorithm | Run 1 | Run 2 | Run 3 |
|---|---|---|---|
| Alpha-beta Minimax | 1318 | 1352 | 1318 |
| Better Alpha-beta | 1365 | 1338 | 1338 |
| MCTS | 1109 | 1107 | 1108 |
| MCTS with UCT | 1392 | 1428 | 1402 |
Graphs of the evolution of Elo ratings look similar for all 3 runs. There’s some variation between the runs, but it looks like Alpha-beta minimaxing is about a 1320, Alpha-beta minimaxing with a better static valuation rates about 1340, Monte Carlo Tree Search with UCT child selection is 1400, and plain Monte Carlo Tree search definitely rates no more than 1110.
I can regularly beat MCTS, but I rarely beat the Alpha-beta minimaxing algorithms, and I almost never win against MCTS with UCT. I would guess I have an 1150-1200 rating against these four algorithms.
Ratings vs algorithmic player tournament
I ran a tournament of algorithmic players. How does the tournament compare to the ratings?
Tournament results:
| Player P | Player Q | Player P wins | Player Q wins |
|---|---|---|---|
| Alpha-beta Minimax | Better Alpha-beta | 307 | 493 |
| Alpha-beta Minimax | MCTS | 651 | 149 |
| Alpha-beta Minimax | MCTS with UCT | 315 | 485 |
| Better Alpha-beta | MCTS | 676 | 124 |
| Better Alpha-beta | MCTS with UCT | 337 | 463 |
| MCTS | MCTS with UCT | 100 | 700 |
I’m using Understanding the Elo rating system as a reference in this section.
Each pair of algorithms played 800 games. The relative strength of Player P to Player Q is:
RP/Q = (P wins/800)/(1 - (P wins/800)), which is calculable from the tournament results.
D is the difference in Elo ratings of Players P and Q, D = RatingP - RatingQ
RP/Q = 10D/400 which is calculable from the Elo ratings above.
I’ll use Run 3 from table well above for ratings differences.
| Player P | Player Q | RP/Q | D | 10D/400 |
|---|---|---|---|---|
| Alpha-beta Minimax | Better Alpha-beta | 0.62 | -20 | 0.89 |
| Alpha-beta Minimax | MCTS | 4.37 | 200 | 3.16 |
| Alpha-beta Minimax | MCTS with UCT | 0.65 | -84 | 0.62 |
| Better Alpha-beta | MCTS | 5.45 | 230 | 3.75 |
| Better Alpha-beta | MCTS with UCT | 0.72 | -64 | 0.69 |
| MCTS | MCTS with UCT | 0.14 | -294 | 0.18 |
Values in columns for RP/Q and 10D/400 should be directly comparable. All comparisons are fairly close. Looks to me like the Elo ratings match the tournament results reasonably well.
Software engineering aspects
I wrote my algorithmic players in the Go programming language.
Each player’s code fits a Go interface,
a kind of object template.
This has turned out to be a benefit.
Having a template made it easier to incorporate new
algorithmic players in both interactive and non-interactive
I only had to do a slight re-write of the program that I used to run my players against each other in order to do Elo rating calculation.
I suppose this is also possible with C++ style or Java style inheritance, but I gave up on those languages years and years ago.