
Mergesort Investigation 8 - bottom up
I thought that since the purely recursive implementation of mergesort didn’t show weird, abrupt performance drops, traversing linked lists (no matter what order the nodes appeared in memory) also did not show abrupt performance drops, and that node size in memory caused different performance oddities, that the iterative implementation’s memory access patterns might be the cause.
To test this idea, I benchmarked another variant of mergesort. I transliterated the Bottom up implementation with lists mergesort pseudo-code from Wikipedia into two Go functions. It has different memory access patterns than either the iterative or recursive versions that I previously wrote and benchmarked.
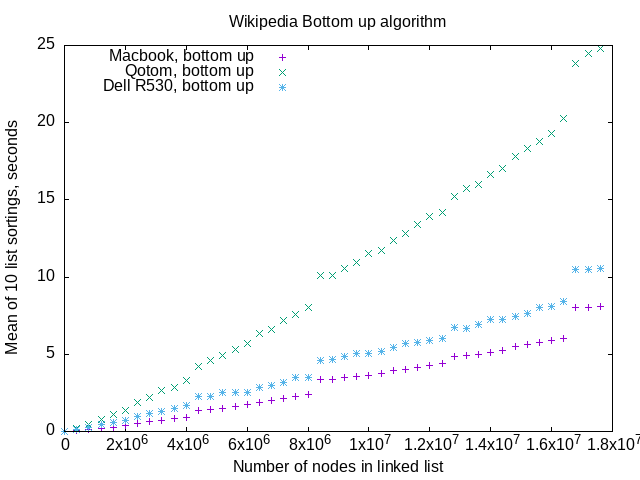
All three machines show the abrupt performance drops at the same list lengths that my iterative algorithm displays.
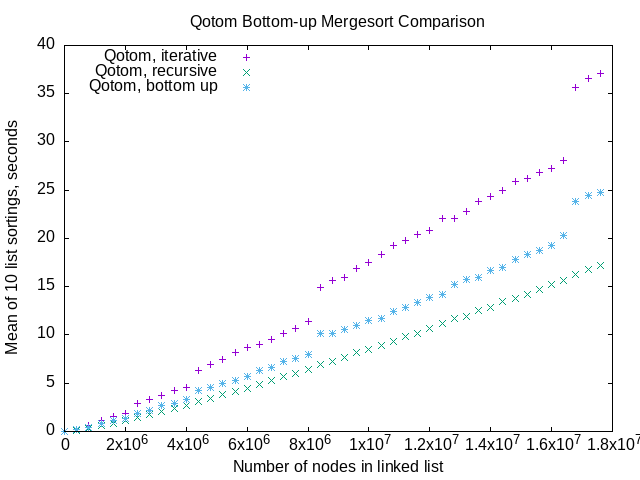
The above comparison of all three algorithms on the Qotom is typical for all three machines. My iterative algorithm is slowest, The purely recursive version is fastest, and does not have the abrupt performance drops. the Wikipedia bottom up with lists is between the other two.
I really don’t know what to make of this.