
Mergesort Investigation 6 - traversing linked lists
It occurred to me that benchmarking traversing very long linked lists end-to-end might provide some clues.
I wrote a program that created linked lists with nodes ordered in memory in four different ways:
- Idiomatic.
- Sorted by node address, where the list head node is lowest in memory.
- Randomized node address.
- Sorted by node address, where the list’s head node is highest in memory. The opposite order of item (2).
The nodes, the elements of the linked list,
have a linear arrangement in memory because that’s how a modern CPU address space works.
The memory “order” is imposed by following .Next fields of the nodes.
The node values are randomly chosen,
so no matter what the arrangement of linked list nodes in memory,
the linked list is unsorted when following .Next pointers from node
to subsequent node.
I ran all four variant memory layouts of linked lists on my three test machines. I got some surprises, but no real hints about why the iterative mergesort has such odd performance.
Idiomatic linked list construction
I’m calling a linked list constructed like this, as “idiomatic”:
for i := 0; i < n; i++ {
head = &Node{
Data: rand.Int(),
Next: head,
}
}
The Go runtime seems to allocate 8192-byte chunks of memory,
each of which holds 504, 16-byte Node structs,
and about 128 bytes of some header information.
The 504 nodes end up in reverse-address-order, from high memory to low.
Sometimes the 8192-byte chunks are allocated from lower memory,
sometimes from higher memory,
so a list constructed this way isn’t strictly high-memory-to-low
or vice versa.
Macbook M2 ARM
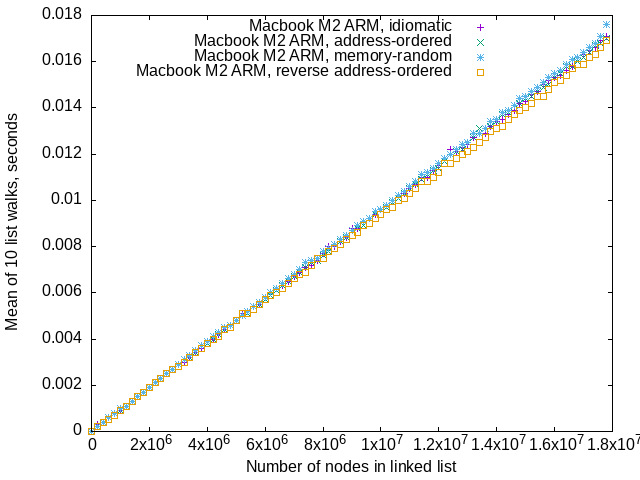
It looks like laying out a linked list with list head in high memory,
and list tail in low memory, with no node at a lower address than
that in its .Next field is marginally faster than other layouts.
This is the fastest among the three machines.
Kudos to Apple for the design of the memory subsystem.
Qotom fanless server
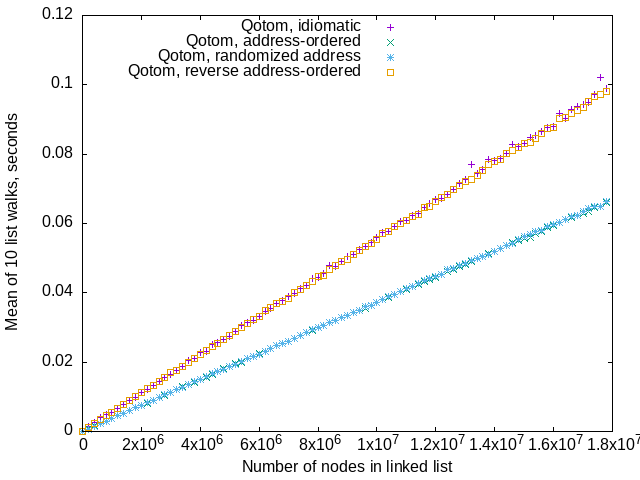
This is just plain weird.
Something about going from high to low addresses via .Next pointer
causes this Qotom fanless server to slow down.
Remember that the “idiomatic” list creating code creates 504 node “runs”
that have nodes with .Next pointers numerically lower than the nodes'
own addresses.
Dell R530 PowerEdge
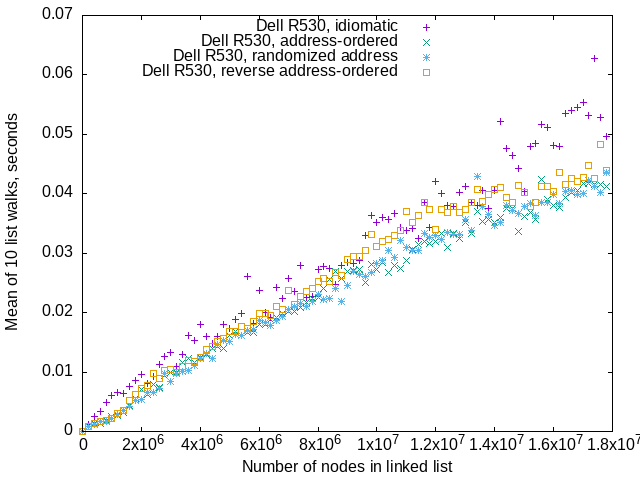
My Dell R530 is slower than my Macbook, and less repeatable than either Macbook or Qotom server. It was built 10 years ago, and designed well before that. It’s still faster than the Qotom, which I bought in 2024.
I hypothesize that the scatter happens because my Dell is also a working server. It does routing to my home network, and aggregates NTP and DNS requests for other machines on that network. The repeatablity of recursive mergesorts on this machine argues against this hypothesis.
Randomized-address lists and address-ordered lists are somewhat faster than idiomatic-ordered lists and reverse-address-ordered lists.
Summary
It looks like benchmark timings (arithmetic mean of 10 end-to-end traverses of a linked list of the same length) are linear with the number of nodes in the list. There are no abrupt performance drops at any list length.
I’m not sure that walking a linked list is a good double-check on the July 2021, iterative mergesort, which repeatedly walks the list by powers-of-two sized sublists. I’m going to post about list traversing anyway, because I did the benchmarking.