
Mergesort Investigation 4 - reuse linked lists
After I wrote a recursive merge sort, I reviewed it to ensure it wasn’t doing extra work. From that perspective, I noticed that for each of the 10 list sorts my benchmark program made for a given length linked list, it created a new linked list.
I thought that I could make the overall benchmark run faster by not creating a new, very large, linked list for every run, but rather re-using the existing list. I hoped to have the benchmark program use less time between the ten measured sort algorithm executions, not make the sorting faster. I surprised myself by getting the opposite effect.
I added code to my benchmarking that used the same linked list nodes for each of the 10 time algorithm executions. The results were interesting. Every length of linked list I benchmarked sorted slower when the program re-used a previously allocated linked list.
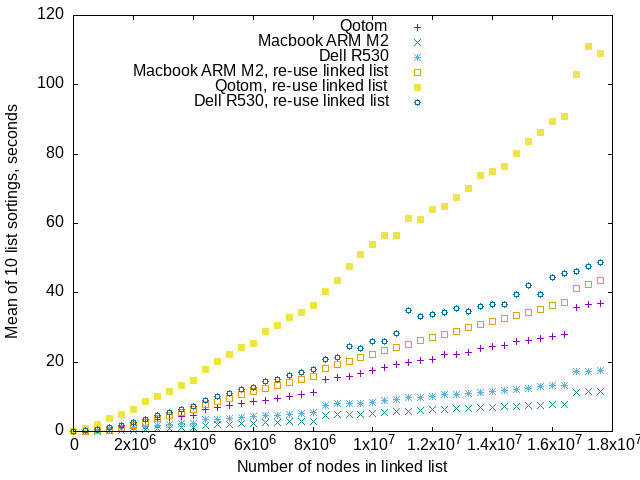
Above, benchmark runs of the iterative algorithm with and without re-using linked lists. It appears that the Macbook M2 ARM laptop is the only machine that shows the abrupt performance drops at 8 million and 16 million node length lists, while re-using those lists.
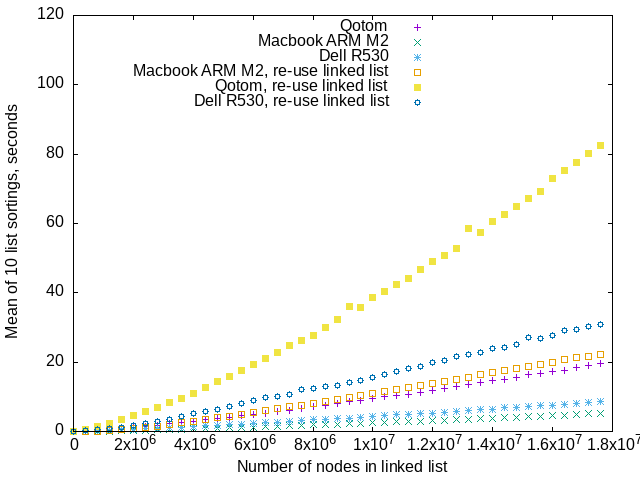
Recursive algorithm with and without re-using linked lists. The recursive algorithm is also slower with a re-used linked list.
Re-using a linked list over and over causes major performance hits.
To an older programmer like me, this smells like the benchmarks used enough memory to cause paging. Modern computers have large enough amounts of RAM that paging probably isn’t occurring.
I wrote a short program to see what addresses and Node struct sizes
my code uses.
My mergesort benchmark program is written in Go
and I haven’t really looked to see what the Go runtime heap allocator does.
To recap, a linked list in these posts is a series of Go structs,
each struct having a .Next field containing the address of another struct Node,
one that’s logically next in the list.
“Logically” is doing a lot of work in that sentence.
type Node struct {
Data uint
Next *Node
}
My short program says that each Node is 16 bytes.
That makes sense on an x86_64 machine.
The “natural” size of an integer will be 64 bits, or 8 bytes.
Even though address sizes (according to lscpu) for my machines
is 48 bits virtual, the physical address size is between 39 and 46 bits.
That’s too big for a 32-bit register, these benchmarks use 8 byte addresses.
8 bytes for unsigned integer .Data field, 8 more bytes for the .Next
pointer field, 16 bytes for the struct.
Apparently there’s no padding for alignment.
It turns out that the Go runtime allocates 504 nodes contiguously in a single, 8192-byte piece of memory. 504*8192 is 8064 bytes. Apparently the Go heap allocator uses about 128 bytes for its own purposes in each 8192-byte piece of memory.
The code for creating an unsorted list of length n looks like this:
for i := 0; i < n; i++ {
head = &Node{
Data: rand.Int(),
Next: head,
}
}
The above procedure makes a list where
most nodes’ address and the value of their .Next fields are close numerically,
usually differing only by the size of a struct Node (16 bytes).
Further, the .Next pointer usually has a lower address in it.
The 504-node sublists in a 8192-byte block
go backwards in memory if you follow .Next pointers.
The address jumps between blocks of 504 nodes mostly go from higher to lower addresses,
but occasionally, there’s a numerically much larger change in address from the
end of one 8192-byte block to the next that can be either higher or lower in address.
Every data point on a graph in these mergesort investigation posts comprises the mean execution time of 10 sorts of a list with randomly-chosen integer data values.
At the start of a benchmark run, a 16-node linked list with randomly-chosen data values between 0 and 16 looks like this, lower memory addresses on the left, higher address on the right:

The Node at the head of the list has a doubled boundary.
.Next pointers are represented by the bold lines joining Node
ovals.
Remember that sorting a linked list doesn’t change the addresses
of the Node structs, but merely changes the values of .Next fields
to contain the address of the next higher-valued Node.
After getting sorted, the nodes’ addresses and .Next fields are typically
not close numerically.
Here’s a representation of the same list, after getting sorted.
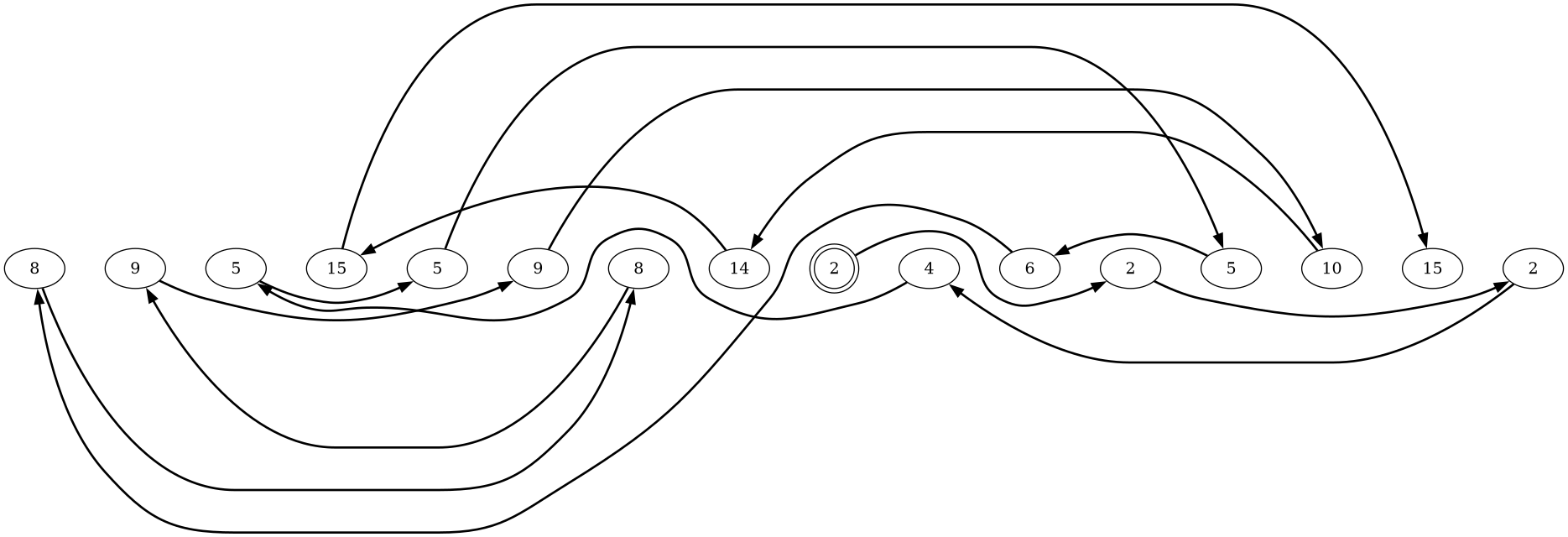
A different node with data value of 2 is the head node of the sorted list, it’s double circled. Changing head nodes means my iterative mergesort is not stable. If you follow the bold arrows, you get numerically sorted values.
2 → 2 → 2 → 4 → 5 → 5 → 5 → 6 → 8 → 8 → 9 → 9 → 10 → 14 → 15 → 15
The re-use code walks a sorted list by .Next pointers,
and gives each node new, different, randomly-chosen integer values,
converting it back to an unsorted list.
In the linked-list-reusing benchmarks, only the first of 10 executions
of a sorting algorithm start with a linked list where the nodes are “near”
each other when referenced following .Next pointers.
The remaining 9 executions of a sorting algorithm start with a linked list whose
.Next pointers contain addresses that aren’t local to the node’s address.
It turns out that both algorithms I wrote, iterative and recursive, are startlingly sensitive to this lack of locality of reference. I don’t think that poor locality of reference is the cause of the abrupt slowdowns because the abrupt performance drops show up in the Macbook M2 ARM benchmarking.